 HIT专家网
HIT专家网

来源:HIT专家网 作者:南京都昌信息科技有限公司 袁永福
前言
升维就是提升事物的维度,使其突破原有的限制,表现出全新的行为和性质。
其实在医学当中早有升维和降维的应用。X光机就是将三维的人体结构降维成一张二维照片,第三维的信息全部重叠混淆在一起,产生大量的信息丢失;而多层螺旋CT就是将二维的人体影像照片升维成三维,从而更接近于真实的人体三维结构。
升维经常会产生革命性的技术进步,从一维条码到二维条码,从二维的X光片到三维的多层螺旋CT片,从三维的牛顿定律到四维的相对论,这些都是升维带来的巨大的进步。
再说明一下降维实现这个名称,它是源自降维攻击。降维攻击出自刘慈欣的科幻小说《三体Ⅲ·死神永生》,从三维降至二维的攻击,由二向箔触发。降维攻击使周围的高维空间向低维跌落,即低维化,导致物体微观结构崩溃解体,并且低维范围迅速扩大。小说中地球文明因被歌者文明发动了降维攻击而毁灭。
升维和降维是物理学概念,本文将其引入到软件设计领域。降维实现就是降低软件设计的维度,也就大幅降低软件的复杂度,简化软件结构,让软件架构长期稳定可靠。因为简单就是可靠。
总体思路是,用升维的手段重新设计整个HIT体系,然后切片进行降维实现。这样来探索大幅改进整个HIT体系的可能性,进而解决当下难于克服的问题。这个思考过程是复杂的、实现过程应该是简单的,所谓大道至简,应该就是这个意思。
这不是一个医疗软件原创小公司的“痴人说梦”,而是对终结医疗软件乱象、困扰的终极思考。希望此文不仅能让医疗软件的开发人员看懂、认可,更能引起医疗行业信息主管的重视。
化解乱象:HIT体系整体升维设计
笔者在《为奋战在HIS创新路上的医院信息科赋能》一文中提出了HIT 7层架构,这个7层架构就是对整个HIT体系进行升维设计。在此进行详细说明。
首先,下图是一个典型的大型电子病历系统解决方案功能设计图:
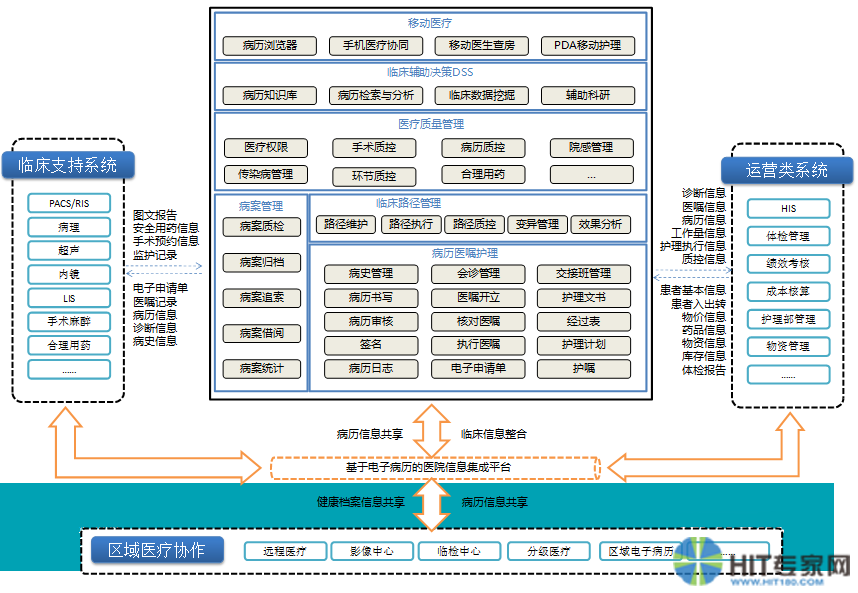
这个设计图是一个二维结构。这个设计图功能模块多,结构复杂,各个模块之间关联甚密,而且需要不断的响应需求变更,追加新的功能。即使是业界大厂才也难于完全自主完成,一般是自主开发一部分,集成一部分。医院耗资过千万元也未必能成功地做出这么大的软件体系。
另外HIT市场算是比较的自由竞争,刚刚新近成立的三大健康大数据“国家队”企业,以笔者目前的眼光并不看好。于是市场难免出现一些混乱,类似下左图的混乱的交通秩序:

混乱的交通往往是无序导致。这时无论道路多宽,都只能是类似于“单车道”效果,此时道路可以看作是一维的,效能是低下的。相同的道路如果经过治理如上右图所示,此时道路是分车道的,各个车道相互不干扰。从一车道变多车道,这可以认为道路是从一维升级到二维。相同的道路,经过升维后效能大大提高。
基于类似的道理,我们可以设想对HIT体系进行治理,于是设计出HIT 7层模型,如下表所示:
| 层数 | 名称 | 简介 |
| 7 | 应用层 | 各种包含业务流程的应用软件,比如各种电子病历系统、护理系统、居民健康档案系统等等。 |
| 6 | 数据展示层 | 各种数据在用户界面的展示和编辑。比如电子病历编辑器、医学集成视图等。 |
| 5 | 数据分析层 | 这里主要是大数据的统计、分析和处理。包括各种查询统计、BI、AI等。 |
| 4 | 数据传输层 | 各种业务数据的传输方式。 HL7、CDA、DICOM、XML。 |
| 3 | 数据组织层 | 医院业务数据的组织关系和派生关系。 |
| 2 | 数据格式层 | 详细描述了各种业务数据包的内容格式。包括电子病历文件格式、DICOM图像文件格式、心电文件格式等等。 |
| 1 | 数据存储层 | 包括各种底层OS的文件系统、数据库、各种大数据的存储模式及安全管控等。各种公有云和私有云架构等。 |
在这里,我们可以将整个HIT体系画出7个大的车道。车道里面还可能需要画出更细的车道。这样各个软件功能模块和产品就在对应的车道中运行,互为支持,互不干扰,共同为整个HIT体系正常运转而服务。
如果HIT体系是一个人体,则数据存储层是脂肪和葡萄糖;数据格式层定义了血液的成分;数据组织层定义了骨骼架构;数据传输层则是血管;数据分析层则是大脑;数据展示层则是表情和语言;应用层则是人体的四肢,能够完成各种功能。
HIT 7层架构理解起来不难。但不知为何在行业内一直没有类似的清晰的顶层设计。在此笔者提出自己的顶层设计,希望能抛砖引玉,引起大家的注意和讨论。以下是对HIT 7层模型的逐层说明。
第七层,应用层
应用层包含了各种包含业务流程的应用软件,比如各种电子病历系统、护理系统、居民健康档案系统、门急诊系统等等。它调用了以下六层提供的功能,并添加医院业务流程和具体的UI界面,是用户使用HIT系统的入口。本文不做详细说明。
第六层,数据展示层
这里包括了各种数据在用户界面的展示和编辑。比如电子病历编辑器、医学集成视图等。例如:
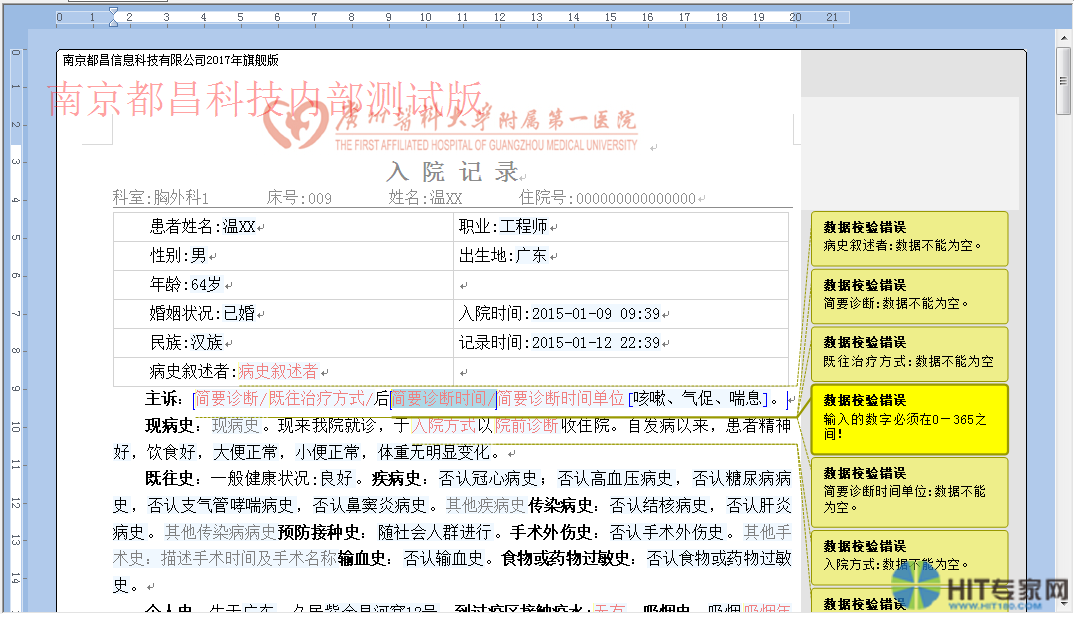
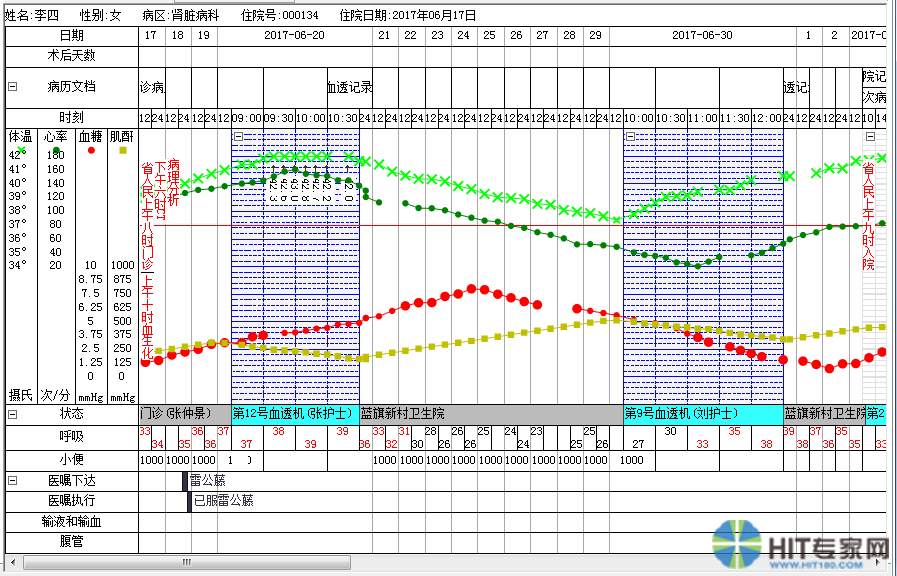
在本层中我们提供电子病历编辑器控件和基于时间轴的医学集成视图控件。具体本文也不赘述。
第五层,数据分析层
主要是大数据的统计、分析和处理。包括各种查询统计、BI、AI等。是HIT体系当前的发展热点。本文也不详细说明。
第四层,数据传输层
数据传输层定义了各种数据的传输方式,官方标准是HL7和CDA,以及DICOM的一部分。本文也不详细说明。
第三层,数据组织层
数据组织层定义了整个HIT业务数据的组织架构。是7层架构的核心层。在这层内部还可以进行更精细的升维设计和降维实现。
常规的软件设计是二维的,比如下图是一个常规的电子病历系统设计图:

这是一个二维的图形来设计电子病历系统。而笔者对其进行升维设计,来设计出三维的电子病历系统。此时就需要采用DOM(Document Object Model,文档对象模型)作为升维技术手段。
DOM模式
DOM是本文的一个基础知识点,虽然和HIT无直接关系,但不理解DOM是无法理解后续内容的,因此在此介绍一下。
一般而言,DOM是默认指定为HTML-DOM,也就是描述HTML文件的DOM模型。W3C国际组织对文档对象模型是这样定义的(摘自 http://www.w3.org/DOM/ )
The Document Object Model is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents. The document can be further processed and the results of that processing can be incorporated back into the presented page. This is an overview of DOM-related materials here at W3C and around the web.
谨翻译如下:
文档对象模型是一种跨平台和编程语言的接口,程序或脚本能利用它来访问和更新结构化的文档。这些文档可以被进一步处理,处理结果可以组成一个有效页面。这是W3C对web上的文档对象模型原理的标准理解。
此处又联想到机械设计的三视图。它是观测者从上面、左面、正面三个不同角度观察同一个空间几何体而画出的图形。这是一种使用多个二维图形精确表示三维结构的方法。以下是原理图:
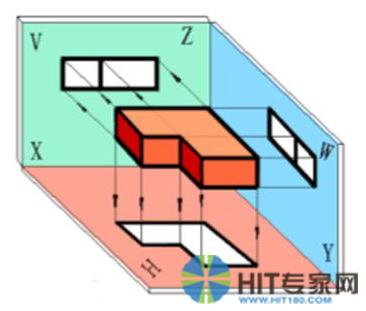
相对于其他的软件的二维设计模式,DOM设计模式是三维的。我们可以参考三视图的原理,使用两个二维图形来表示DOM的三维结构。
以下是DOM的数据组织结构图:
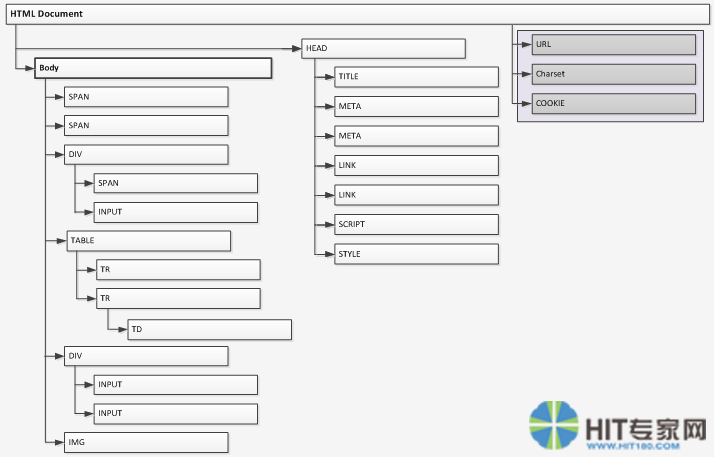
这个结构图中表示一个document包含一个head和body节点。head节点下包含title节点和若干个meta节点等等。而body节点包含若干个span、div、table节点,而这些节点还包含若干个子节点。如此形成一个树状结构。
以下是DOM的元素派生关系图:
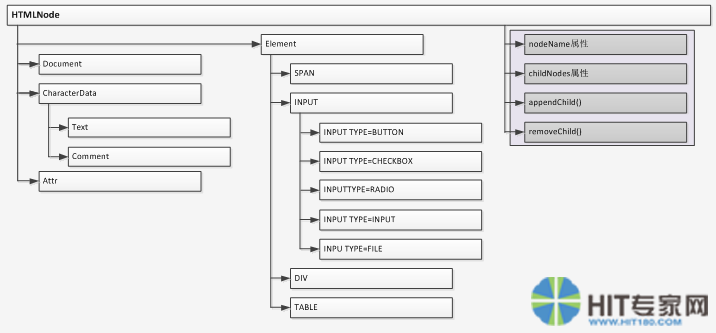
这张图表示出如下的派生模型:
HTMLNode→Element→INPUT→INPUT TYPE=BUTTON
HTMLNode→Element→SPAN
HTMLNode→Document
HTMLNode→CharacterData→Text
等等。
由于DOM中的各种文档元素具有派生关系,可以想象出在上一个的DOM数据组织结构图中,各个元素节点从屏幕出发朝向读者按照派生关系进行着带层次的生长(类似3D打印);这就突破了计算机屏幕的二维限制,而形成三维结构。(有点像《午夜凶铃》中的贞子从二维突破成三维。)
这样类似机械设计的三视图,我们使用DOM组织结构图和DOM派生关系图两个二维图形来描述出一种三维的数据模型。
在此笔者归纳出的DOM概念内涵:
1.所有的文档对象元素类型都是从一个基础元素类型派生的,文档对象类型都在基础类型上扩展实现了各种行为。
2.每个文档对象都映射了文档中某个片断,修改文档对象就等价于修改文档片断本身。
3.文档对象可以有子节点,由此构成一个多层次对象树状结构。
4.存在一个顶级对象,用来表示整个文档。可以宏观控制整个文档,也是应用程序访问文档对象树状结构的唯一入口。
5.文档对象模型是可编程的,应用程序通过访问文档对象模型来访问结构化文档。
6.大部分类型的DOM可以将整个文档结构保存到一个文件中,也可以从一个文件中再现整个文档结构。这算对象序列化。但也可能有例外。
DOM比较难于理解和掌握,是一种超出行业平均水平的高级软件设计模式,也是本文后续内容的基础,关于DOM的详细理解可参考笔者的文章:http://www.cnblogs.com/xdesigner/archive/2008/06/04/1213504.html。
DOM是W3C国际组织制定的国际标准,是所有WEB应用的基础,其影响力远超HIT体系中所有的标准,秒杀HL7和CDA。它历经全球几千万的开发者十多年的实践证明,它是坚实可靠的,进而证明DOM模式的软件设计模式是非常具有价值的。
EMR-DOM
所有的电子病历系统是以病人为中心的,而所有的病人都属于地球人类这个物种而存在高度的相似性;而且电子病历业务数据主要就是对病情及诊疗的描述;所以,各种电子病历系统中的业务数据是具有很大的相似性的,这样就有了将医疗业务数据规范化、标准化的可能性。
于是我们参考HTML-DOM的原理,可以设计出EMR-DOM,就是对电子病历中所有的业务数据按照DOM的方式进行整理,建立起三维数据模型。EMR-DOM的组织结构图如下:

而EMR-DOM的派生关系图如下:

这张图表示出如下的派生模型:
基础类型→查房→主治医生查房
基础类型→查房→主任医生查房
基础类型→手术→门诊手术
基础类型→手术→急诊手术
基础类型→手术→住院手术
等等。
这个三维的数据模型就比传统的二维数据模型提升了一个维度,这就使得EMR-DOM具备了很大的优势。主要有:
第一,强大的可扩展性。EMR-DOM是OOP在数据建模中的深度应用,具有OOP本身带来的强大的可扩展性。比如,医院新增了机器人手术,则EMR-DOM可以进行局部扩展,如下图所示:
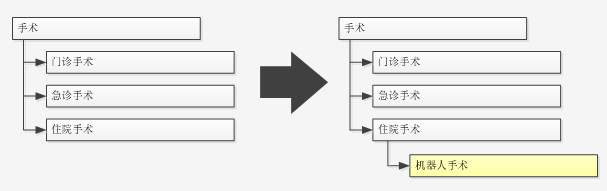
这样就让EMR-DOM能支持机器人手术。EMR-DOM能在深度和广度两个维度进行扩展。相比而言,传统的软件模型只能进行广度这一个维度的扩展。
第二,稳定性。EMR-DOM能不断添加新的功能而不影响已有功能。使得EMR-DOM具有很好的稳定性。大部分功能模块具有长久的生命力。基于EMR-DOM的投资,会得到很好的保护,避免了不断的推倒重来。
第三,可普及性。EMR-DOM是基于DOM的,而DOM是主流的国际标准。大多数开发组织未必深刻理解DOM思想,但在开发实践中已经大量运用DOM的套路。因此EMR-DOM具有很好的群众基础,制定出来后很容易让大多数开发组织理解和应用。因此普及起来困难不大。
第四,开放性。EMR-DOM是用于描述医疗过程业务数据,医疗业务数据有其客观存在的规律,不受少数商业组织的意志所决定。因此EMR-DOM可以做的比较中立,而较少的受到商业利益的干扰。这样具有很好的开放性,任何组织都可以基于EMR-DOM做出自己的软件。从底层开始就能做到互联互通。这个时候EMR-DOM就成为一棵树,大家都围绕着这颗树浇水施肥,促其朝着四面八方生长。
第五,优雅的设计。工程技术是解决具体的问题,它发展到了一定的层次就成为工匠艺术,变得优雅起来。优雅就导致简单,简单就导致能快速普及,快速普及就能带来大效益。EMR-DOM从整体上看以及从一些分支的细节上看,都存在一定的相似性,是一种递归的设计模式、每次递归的套路都是一样的;已经具有艺术的意味了。
HIT-DOM
更进一步的,参考EMR-DOM的建立,我们就可以建立LIS-DOM、PACS-DOM、门急诊-DOM等等一系列的DOM模型。而这些DOM模型最后可以综合起来形成HIT-DOM。
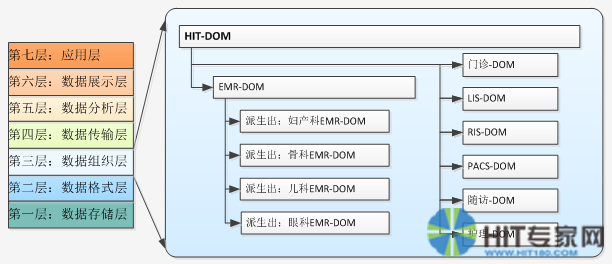
HIT-DOM是一个终极的DOM模型,用于描述整个HIT体系的所有的业务数据。整个HIT体系数据种类繁多、数据量巨大、而且经常按需变化,传统的二维的数据模型是无法处理的。只有采用三维的DOM数据模型技术才有可能完整的管理起来。这就是软件的升维设计带来的巨大的进步。
闭环的世界
HIT-DOM不单可以描述业务数据,还能添加一些基础业务流程。比如在EMR-DOM中具有这样的局部结构:
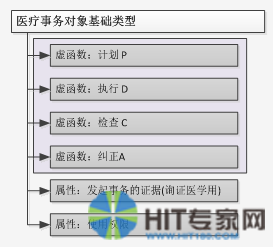
在这里医疗事务对象基础类型中添加了对PDCA的支持。所有从基础类型派生的医疗事务对象都具有PDCA的可能性,形成一个闭环管理结构。而且DOM具有递归扩展的,因此闭环管理可以是从微观到宏观的一路持续下去。最开始是形成个人的居民健康档案的闭环,如下图所示:
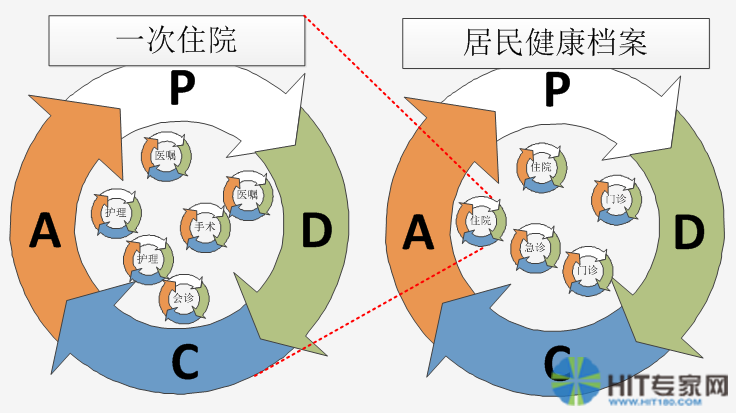
然后发展成区域居民健康档案的闭环管理:
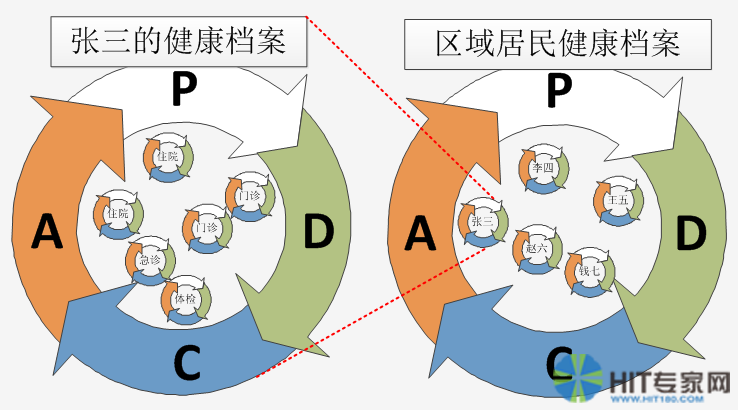
最后发展成国家居民健康档案的闭环:
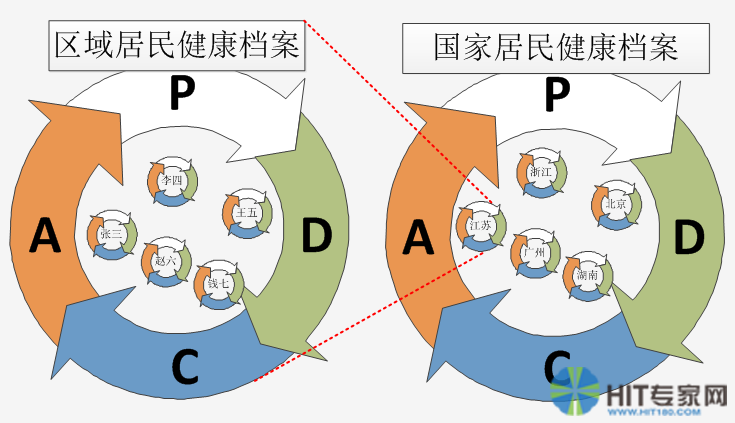
这也体现了DOM递归重复扩展的特点,为设计国家居民健康档案系统提供了一个新的思路。
化繁为简:降维实现
上面的HIT-DOM是对HIT体系进行了升维设计,将一个高度复杂的问题整理一下,建立起三维的理论结构,然后把结构逐层切片,将三维结构切成多个二维结构,降低每个切片的实现难度,改进项目管理,从而最终整体解决问题,这就是降维实现。
和HIT 7层模型的实现不一样,HIT-DOM的实现将是一种滚雪球的模式。首先建立一个很小的核心,所谓的HIT-DOM奇点。奇点的建立比较关键,奇点太大会限制未来整个HIT-DOM的扩展能力,奇点太小会羸弱得不足以支撑后续发展。因此需要统计分析大多数医疗业务数据的特性,挑选出一个大小合适的特性交集,形成奇点。
奇点建立之后就需要不断的在外面层覆盖各种扩展出来的数据模型,每个数据模型就是一个二维的片状结构。越靠近奇点越抽象,越外面越现实。这一层层叠加就构造了一个三维结构。在HIT-DOM的生长过程中仍然需要不停的调整奇点来适应当前架构。
都昌公司未来几年将建立这个HIT-DOM奇点,并构造出最基础的架构,这项工作难度非常大。因此目前正在找精通HIT业务及技术的人才和组织,然后一起合作完成这个事情。
HIT-DOM奇点建立起来后,将成为都昌开发支撑平台的内核之一对外提供服务。其他开发组织将从奇点开始建立起各自领域的HIT-DOM分支,我们也将参考合作伙伴们创建的HIT-DOM分支来不停的完善发展HIT-DOM体系。
HIT-DOM建立起来,各种医疗组织之间的数据互联互通具有了扎实的基础。个人的数字医疗及健康档案也很容易实现。所有的HIT系统就围绕着HIT-DOM运作,这就统一了系统运行模式,整个HIT体系变得透明一些而更易于建设和维护了。
第二层,数据格式层
数据格式层定义了HIT体系中的一些数据包的格式。比如DICOM、CDA属于这层的范畴。流程似径,数据若水,流程再完美,其中流的水是污水、不能利用的水则也是枉然。而数据格式决定了数据是否利用,能利用的程度。因此公开、透明、标准的数据格式是HI体系高效运作的基础。
对于数据格式层,我们提出了M-DOM和T-DOM。如下所示:

通用病历文档对象模型,Medical Document Object Model,简称M-DOM,W3C DOM技术在病历文档领域中的应用。它是一种专门用于精确描述病历文档内容的软件设计模式。它利用一个个可编程实体映射到文档的各个部分,这些实体基本上按照树状结构组织在一起,各种实体类型之间存在派生关系,其他软件通过这些可编程实体来访问文档内容。
时间轴文档对象模型,Timeline Document Object Mode,简称T-DOM。是一种对整个HIT业界来讲都是全新的文件格式。对于时间轴文档有一个不精确的浅显说法,就是将体温单保存为一个文档。这个时间轴文档不是图形,而是仅仅包含纯粹的数据和图形设置格式信息。
T-DOM包含了一段时期内容所有的护理数据,比如体温、脉搏、体重、心率、检查检验指标、各种医疗事件等等。它避免了护理系统对外开放详细数据接口,同时提供各种护理数据的离线浏览。这为远程会诊、三级诊疗等提供了全新的赋能控件。
而且T-DOM文件只包含纯数据,文件大小可能只有几十、上百KB,性能很好,可高频使用。
数据格式层将后后续文章中详细说明。
第一层,数据存储层
数据存储层用于长期存放HIT体系产生的大量数据。长期以来,业界主要采用关系型数据库来存放数据。随着技术发展和行业新需求,现在出现一些NOSQL类型的数据库来存储数据,特别是用于存储大量的非结构化数据和文档。
很多人设计系统是以数据库为中心的,但笔者觉得应该是以数据结构为中心,即以HIT-DOM为中心的,而数据存储层只是HIT-DOM的对象序列化的地方,是数据睡觉的地方。沉睡的数据是不产生价值的。
下图是常规的HIT数据存储层的结构设计:

在这个结构图中,数据存储层包含操作系统的本地文件系统、传统的关系型数据库、FTP服务器、WEB服务器,或者类似mongodb的NoSQL数据库。上层模块要调用数据存储层的功能是需要编写相应的接口模块,而且还可能需要考虑本地缓存和文档权限管理模块。这导致上层体系添加不少代码,而且逻辑上讲本地缓存和权限管理也不应该是上层体系的范畴。
在HIT系统中,很大一部分数据是文档,比如电子病历文档、护理文书、医学影像文件等等。将这些数据存在关系型数据库中是比较麻烦的,为了解决这种普遍存在的基础型问题,我们提出了虚拟文件系统。
虚拟文件系统
虚拟文件系统(VFS,Virtual File System)的原理如下所示:
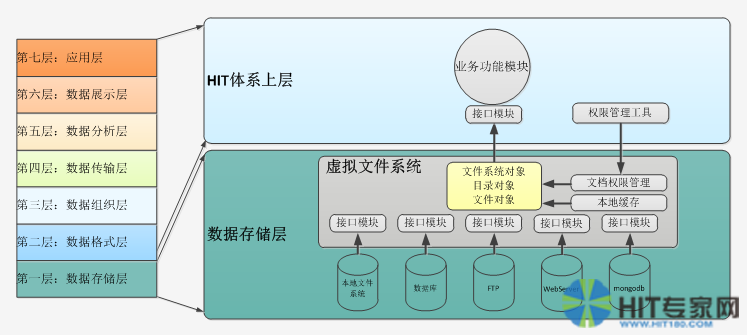
虚拟文件系统中首先构造了一个抽象的文档存储的开发接口模型,该模型包括文件系统、目录、文件这三种可编程对象类型。目录可以包含子目录和文件,文件提供读写文件内容的虚函数。上层体系可以仅仅按照这种抽象模型来调用虚拟文件系统的功能,可以据此实现递推遍历目录和文件结构、读写文件内容。
虚拟文件系统还内置接口模块,将目录和文件操作映射到本地文件系统、数据库、FTP服务器、WEB服务器或者类似mongodb的NoSQL数据库。而且提供开放接口模型可以可供未来扩展实现新的存储模式,比如支持私有云、共有云之类的。
虚拟文件系统还内置类似Windows文件系统的文件、目录访问权限的设置,其界面如下图所示:
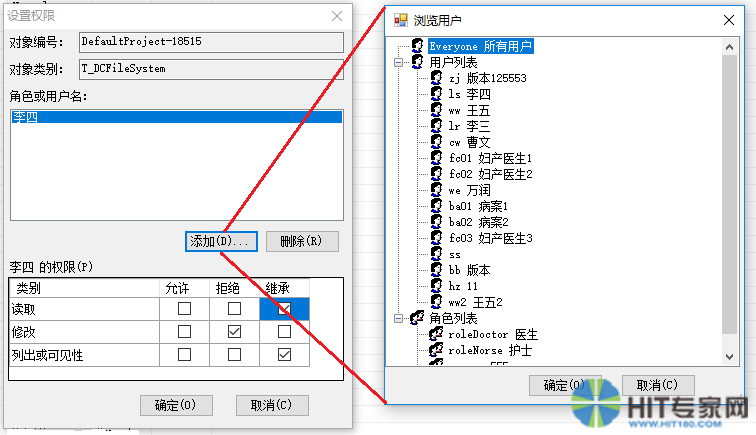
虚拟文件系统具有编程接口,可以将HIS中的用户名和角色映射到虚拟文件系统中使用的用户名和角色。这样就能统一管理授权,统一编程接口,提高开发和运维效率。
使用虚拟文件系统,上层程序仅通过标准的模式来处理文档的存储,而无需关心底层具体如何实现的。比如对于小型应用,我们设置虚拟文件系统是基于本地文件系统或者数据库的;而对于大型应用,可以设置为FTP服务器或者mongodb数据库。这样,上层程序功能无需修改就能用于小型应用和大型应用,提高业务功能模块的重用程度,提高系统效能。
虚拟文件系统提供本地缓存的功能,这对上层也是透明的,这也能降低上层软件复杂度,提高系统网络I/O效率,提供系统性能。
都昌开发支撑平台
都昌公司作为HIT行业中的技术先驱,初步设计出HIT 7层架构,并选择了某些无人区进行革命性的技术探索。并将一些先进的技术探索成果产品化,发布了都昌软件开发支撑平台,为整个HIT行业的开发组织(包括医院信息科和软件公司)赋能,赋予他们更为强大的软件研发能力。这样帮助HIT开发组织掌握先进的生产力,进而更容易开发出符合自身情况的软件产品。
都昌开发支撑平台和其他公司的数据集成平台、应用平台有着根本的区别。其他平台是面向医疗机构的完整的软件成品,能独立运行并解决一系列的问题。而开发支撑平台是软件中间件,运行着蓄势待发的软件功能模块,需要进行一些二次开发调用才能发挥能力而成为一个独立运行的软件成品。其详细对比如下:
| 比较项目 | 都昌开发平台 | 其他平台 |
| 产品定位 | 软件中间件 | 独立的软件成品。 |
| 编程接口 | 丰富,完全开放。 | 很少或基本没。 |
| 独立运行 | 不能独立运行 | 能独立运行。 |
| 目标客户 | 开发组织,包括自主研发的医院信息科和软件公司。 | 终端用户,主要指医院。 |
| 软件架构 | 灵活、高度可配置。 | 固化。 |
| 运行环境 | 宽松,限制少。 | 有特定限制。 |
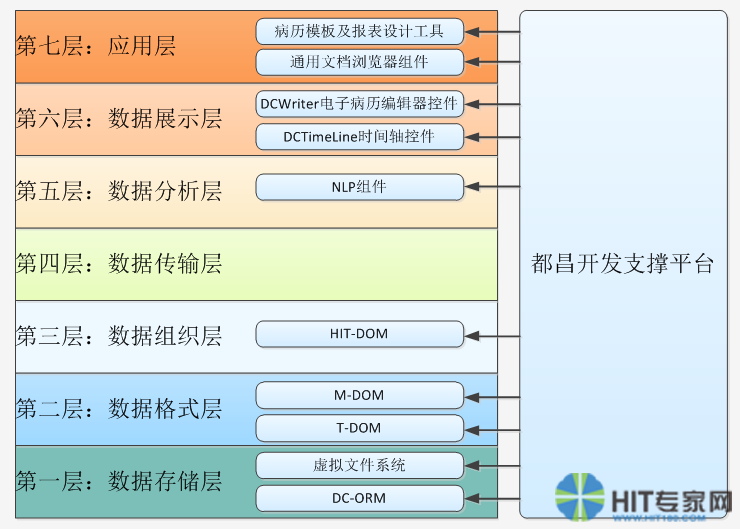
目前都昌开发支撑平台已经包含了虚拟文件系统、电子病历编辑器控件、基于时间轴的医学集成视图、病历模板及报表制作工具、集成文档内容浏览器、NLP、统一授权控制等诸多赋能组件。
未来平台将包含HIT-DOM奇点及HIT-DOM核心模块,希望能引导整个HIT行业的开发力量。下图是都昌开发支撑平台的功能模块图:
结束语
从0到1是奇点,从1到多是升维,从多到1是降维。把整个HIT体系经过分析提升维度,然后切片降低维度,然后在更细分的领域再升维设计、降维实现。这样迭代反复重构,从而改进整个HIT体系。高能效的HIT体系在当下的DT时代能有效帮助解决中国医疗体系中的诸多问题,使其能更能实际的配合新医改,为医院和患者带来便利。凡事贵在知行合一,南京都昌信息科技有限公司未来几年都将朝着这个目标努力向前。
【作者简介】
袁永福,男,南京东南大学毕业,微软MVP,南京都昌信息科技有限公司创始人,长期从事电子病历编辑器控件的研发和推广工作,其产品成为编辑器细分市场的第一品牌。(邮箱:28348092@qq.com)

【责任编辑:孙鹏】



{kind=link}
写得真心很好,很赞同。升维化简为繁,可以深入分析业务。降维又化繁为简。七层的顶层设计,各司其职,清晰明了。可知行合一,却让我头疼。项目工期紧张,整个院内信息系统厂商林立,如此顶层设计工程庞大。原有系统改造也是困难重重。