 HIT专家网
HIT专家网
来源:HIT专家网 供稿:腾讯健康
【编者按】
当前,腾讯健康正在全力构建数字健康的“两面四桥”,借助自身储备的技术能力、连接能力,致力成为医疗行业信息化的“数字化助手”,实现“科技向善”的品牌愿景。HIT专家网开设【腾讯健康专栏】,通过一系列技术文章介绍腾讯健康业务深耕方向、技术解决方案与落地案例等,敬请各位读者关注。
当前医疗行业对数据的需求不再单纯是录入数据与获取数据,而是在录入和获取正确数据并经正确加工后,在正确的时间把正确的数据推送给正确的人。在不同的医疗业务场景中,用户对数据质量的需求不尽相同,除了主要关注数据的准确性和一致性以外,还会关注数据的实时性和相关性。专业的医疗领域和粗糙的数据质量现状,形成了行业壁垒和门槛,让一些非医疗行业的厂商在医疗大数据外缘徘徊。
数据治理流程涵盖从数据建立标准到数据应用(如图1所示),这套方法论兼顾了通用的数据治理原则,同时还考虑到特殊性。按照这套方案进行医疗数据治理流程的设计,在一定程度上可以保障数据质量。
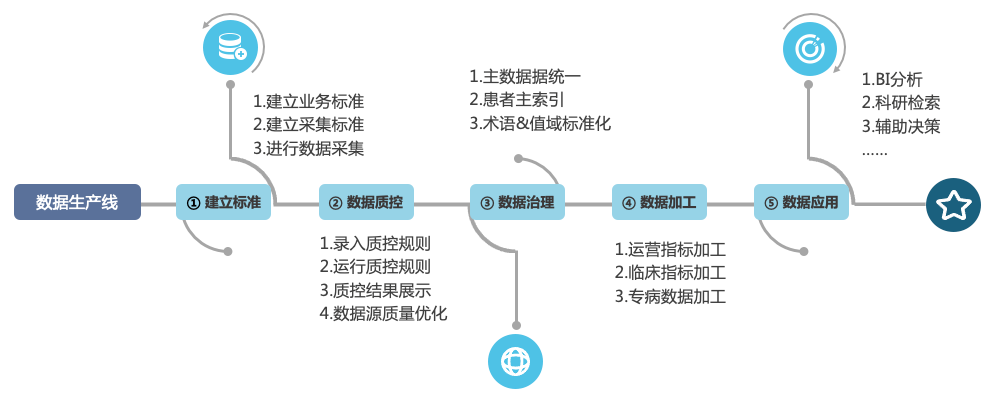
在方法论准确的前提下,执行能力非常重要。医疗数据治理的数据量大,数据明目乱,数据处理的过程不被理解,耗时漫长且难以直接呈现价值。在考虑经济性和实用性等情况下,部分厂商会降低数据治理相关的要求。因此,在数据治理流程每一步工作中付出的努力,将与取得的成果形成正比。
根据多年大数据处理经验,腾讯健康数据中台认为,推动医疗数据治理的良性发展,需要把握三个基础原则,即:建立评价标准、过程透明、内容积累。
建立评价标准
事实上,医疗数据并不缺少行业标准,国家卫生健康委对数据元、数据集以及数据应用需求等都已制定相应规范。医疗行业缺少的是对数据质量的评价标准。
所谓“建立评价标准”,既需要定义医疗业务数据集(依赖于应用数据及数据采集范围需求),也要定义数据内容的质量要求,还要对数据治理效果进行质量评价。
数据质量可以提升。但越往上提升,消耗的人力物力和流程调整难度将成倍增加,因此比较合理的做法是结合实际、按需治理。以往,数据治理都是“自下而上”的运行方式:在目标不清晰的情况下,数据开发工程师的工作周期结束时,数据质量则自然停滞;业务部门在使用时才发现数据质量未达到预期效果。
根据当前情况进行问题的溯源,关键在于增加“自上而下”的数据治理需求:业务部门应清晰数据效果,数据质量应确保数据范围,包括梳理业务需求数据、制定数据质量要求,同时确定评价标准体系等。
我们查看一个医院实际案例:在医院等级评审中,“出院患者手术占比”指标的准确率应在99%以上。为了实现这一目标,病案号的填充率、病案手术编码与病案首页表的关联度至少要达到99%以上(如图2所示)。经过类似这样的分析,可以梳理出每个指标所需的质控规则和评价要求,其后在STG、ODS数据仓库配置相应的质控规则及数据工作流,就可以按照相关要求发现和排查问题,按需进行数据治理。

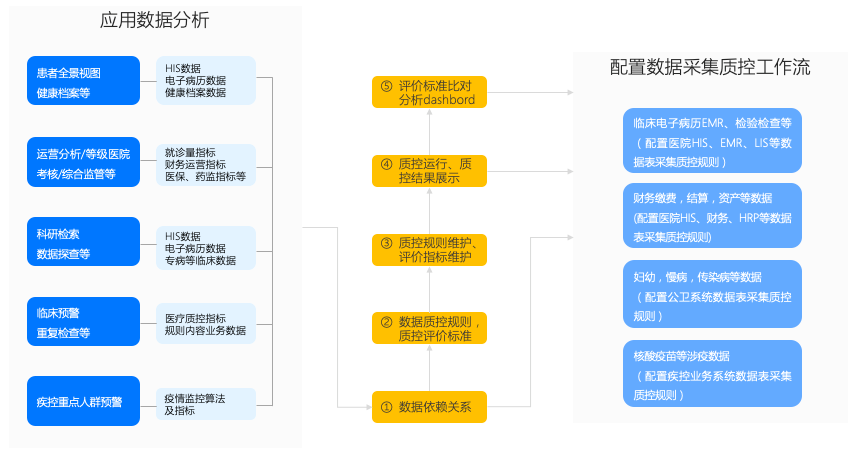
如何梳理各项业务指标的质控规则和评价要求?图3是几类常见业务应用数据质控分析的拆解流程。从原始业务环节到最终使用环节,需要对数据进行哪些质控、应治理到什么程度、最终合规率应达到90%还是99%?对过程中的各个细节进行分析、标注,质控规则和评价要求也就自然产生了。
过程透明
“过程透明”即建立一站式、可视化的数据工作站,将数据治理过程工程化、将治理结果透明化。一站式、可视化的工作流将覆盖整个数据治理周期,一方面让操作便捷化,另一方面,过程中的监控既能快速定位问题,也能保障数据流向安全。
一站式、可视化的工作流主要包括以下环节:
(1)建立数据标准。包括数据采集标准、业务主题标准和元数据,并在此标准之上建设数据仓库,配置所需的质控规则,以及最终质控结果的评价指标。
(2)搭载数据治理算法。医疗数据的治理需要经过结构映射、术语标准化、病历结构化、EMPI等处理。如图4所示,这些算法或SQL语句可以灵活地在可视工作流上进行配置加载,减轻数据治理工作量。

(3)运行质控规则,计算质控结果,对比评价指标,展示数据质量监控信息。面向不同场景的质控Dashboard,针对不同场景的不同侧重点进行差异化展示;对没有达到评价指标的质控数据,支持进行下钻与问题定位。
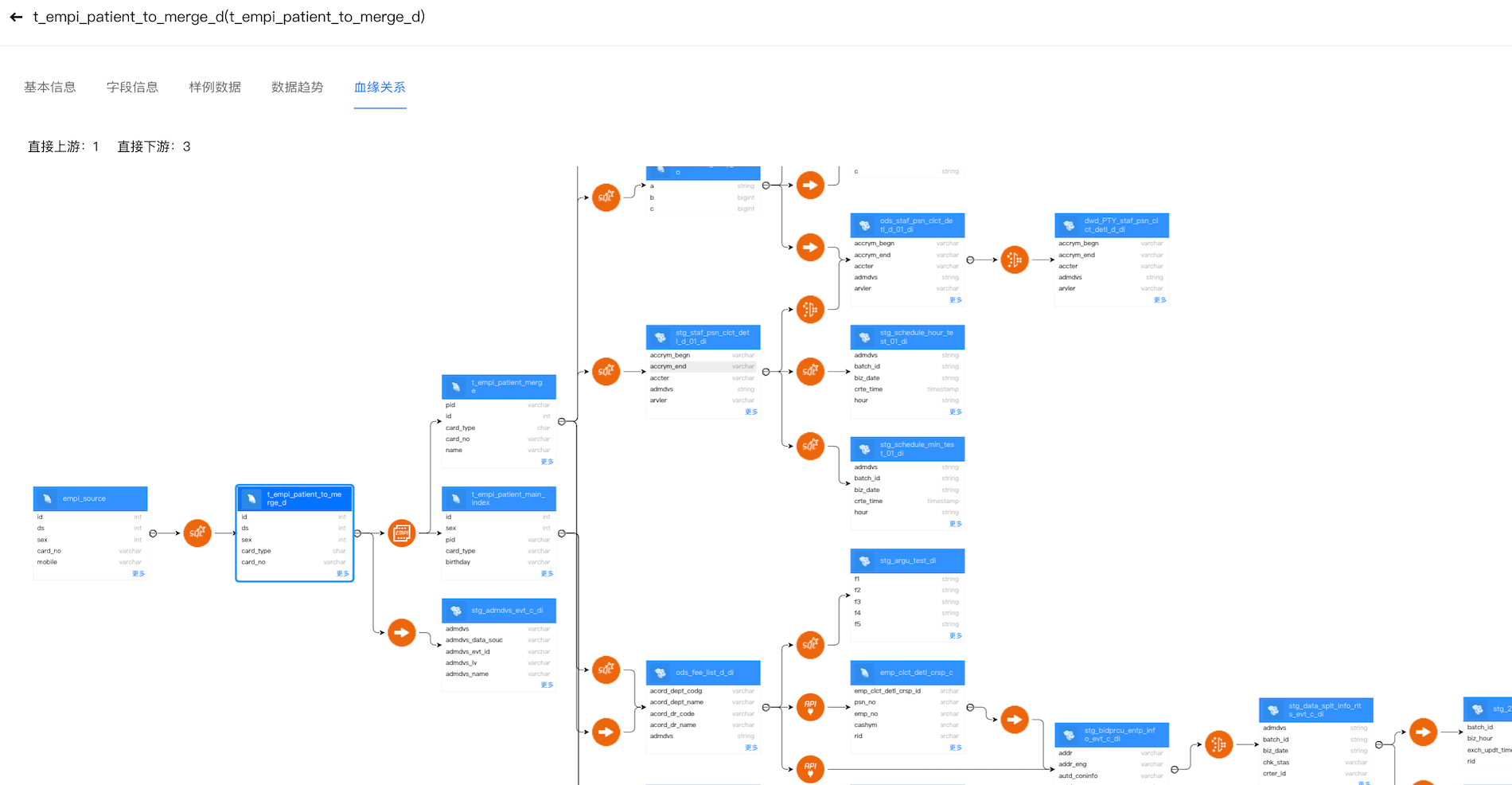
(4)数据加工挖掘。包含运营指标生产、临床专病数据、人群标签挖掘等。“一站式、可视化数据工作站”让数据治理的所有工作都可在一个可视化平台进行完成。这种方式有别于以往离散拼凑工具的方式。首先,工作站可从元数据开始,建立直至最终业务数据应用的全链路数据血缘关系(如图5所示),可以获悉任意数据发生的变化,追溯关联质控问题;其次,数据流动透明,业务需要什么数据,可通过快速建立数据使用通道的方式,从来源采集到治理加工实现业务逻辑的流程化,操作便捷;第三,过程透明,数据都在平台内完成,这就间接实现了数据沙箱的功能,让数据操作可监管、更安全。在规范建设和管理工具的双重作用下,数据治理可真正实现标准化与工程化。
内容累积
“内容累积”,是指在一站式、可视化数据工作站的增持下,无论是治理规则还是指标加工规则都能沉淀在平台上,让这些基于业务梳理的规则下沉进而共享。数据治理的工作进行得越多,医院的数据资产累积就会更精细化,最终让之前“看不到的价值”体现出来。
当下几乎大型医院都建有自己的数据中心,都在进行数据治理。但每当有新应用时,厂商都需再次进行数据治理,重复性极高。这个现象反映的问题是数据治理的内容和结果并未得到有效沉淀,总会出现头痛医头、脚痛医脚的现象,最终多个项目呈现的统计指标相互矛盾,一个数据中心变成了“混搭积木”,业务人员花费大量精力梳理的治理规则以及口径,也没有在各个业务系统得到统一贯彻。
只有将数据治理的底层筑牢,才能通过层层建设将上层应用的效果体现出来。构建数据体系是一个长期积累过程,前期医院需要搭体系、铺平台,让各系统厂商可以将业务数据内容在医院内部得到积累。经过前两个环节的工作后,可以根据不同业务的需求,进行数据挖掘、加工等工作,同时将各项医疗业务的数据需求进行分类,并发现基于人、患者维度的画像标签生产,其中既有基于事实的统计指标加工,也有基于疾病逻辑的医学指标等。
不同的医院业务部门会在不同业务场景中使用这些数据。比如,病种质控指标需要在医务上报、临床预警场景中使用,在病历书写以及主任查房时也需要查询4-5个业务系统。如果能在数据层将这些积累的数据内容实现共享,在业务层就可以被直接引用,从而让业务数据化,同时这些数据不单是一个业务所需的,可以相互赋能。
累积这些内容,是医院知识管理的重要方式。无论是业务规则、统计指标还是画像标签,都是医院运营和质量管理思路的表现形式。以往这些内容封闭在不同厂商的系统中,如今通过可视化数据中台,可以沉淀下来并转换成可以直接使用的数据资产。
以上三点内容并不是新概念,但真正结合、落实到医疗场景才能发挥作用:“评价标准”是医疗业务的数据化,“过程透明”是将数据治理加工工程化,而“内容累积”是将数据资产化,并再次赋能业务实现共享。
在这三个原则推动的数据治理模式下,医疗数据精细化的“雪球”将越滚越大,不论是厂商迭代还是系统更替,影响的不过是冰山一角,底层的数据核心将会一直掌控在医院自己的数据资产里。
如有关于医疗健康大数据相关咨询,请联系tencent_healthcare@tencent.com 。

精彩不容错过!

我们将尽快与您联系!
【责任编辑:陈曦】



评论前必须登录!
注册