 HIT专家网
HIT专家网
来源:HIT专家网 记者:朱小兵 特约通讯员:许艳艳
【编者按】8月30日,南京。中国科学院院士、中国科学院生物物理研究所研究员陈润生应邀在此间举行的2016年中国卫生信息技术交流大会上做主题报告,全面深刻阐述了他对大数据与精准医学的理解。陈院士凭借学者特有的严谨性,针对人们十分关心的精准医学的种种疑问,做了深入浅出、抽丝剥茧的生动阐述。尤其是他在整个演讲中提出一个核心观点:关于基因组学数据,人类目前能解读的仅有3%。其余97%的未知领域,既是实现精准医学之路上的严峻挑战,更是广阔的创新机遇。由此,陈院士向我们揭示了更多关于精准医学的“真相”。
HIT专家网在此将陈院士的演讲全文整理如下,供感兴趣的读者参考。由于整理此稿所需的专业性超出我们从事的专业,相关文字表述出现纰漏在所难免,欢迎读者不吝批评指正。
2015年1月20日,美国总统奥巴马在国情咨文中提出,要在美国开展精准医学的研究。从那以后,精准医学在世界范围内迅速成为一股潮流。中国也不例外,最近精准医学的科研专项已经立项,而且通过了两次评审,已经落实到六十几个项目。
一问:精准医学的核心是什么?
什么是精准医学?精准医学的核心是非常具体、明确、集中的,就是组学大数据和医学的结合。
自上世纪90年代开展的基因组研究以来,通过破译人类的遗传密码,科学家发现了非常多的分子水平的位点和疾病直接相关。当时,大家就想到,如果把这些信息应用到临床医学,就一定能够提高医疗诊断的效率,改善治疗的结果。这时,出现了转化医学、个性化医疗。现在,这样一种趋势逐渐被精准医学一词所代替。不管是转化也好,个性化也好,都是为了让医学的方案更精确。所以,精准医学的核心非常具体,就是把组学大数据用到医学,特别是临床医学当中。
二问:精准医学能给医学带来什么样的本质变化?
精准医学把组学数据用到临床,改善临床效果,这是不是能够构成医疗体系的重大变革呢?我认为,它有可能使得,当前以医疗、医生、医院为主的医疗救治模式,过渡到以对面向全民健康教育、健康评估和健康干预为主的健康管理模式。这样的转变是带有根本性的,并有可能带动新的产业改型换代和升级。
有人估计,到2018年,全球跟精准医学相关的市场规模将达到2000亿美元。因此有人评论,精准医学研究已经成为新一轮国家科技竞争和引领国际发展潮流的战略制高点。美国积极开展精准医学的研究,要测100万人的基因组。欧盟、日本也在开展相关研究。尽管各国都很关心这件事,但是如果大家去查一查,就发现各国的投资并不是很大——这是精准医学很特别的地方,不是一次大规模投资就能解决问题,而是一个逐渐求证、试错和完善的过程。
三问:精准医学可以在哪些方面改善目前的产业结构?
首先,精准医学可以促进生物样本库和数据库的发展。我们现在数据库的样本都是小规模的,面对精准医学百万数量级的样本,建超大规模的样本库和数据库将是一个新型的产业模式。
其次,有了样本库和数据库,要进行组学测量,以基因组为代表的组学数据的挖掘和测量,将是第二个可能引爆的新产业。
第三,有了数据,有了样本,我们将会得到非常非常多的新的数据,通过对数据的分析,可以得到非常多的和疾病相关的分组诊断标准,也可以对药物设计提供全新的分子靶点。这是第三个可能出现的产业——新兴的分子诊断和靶向药物设计。
四问:怎么样才能实现精准医学?
第一,就是建立组学大数据的基础。首先要获取海量人群的组学数据。所有组学数据都是大数据,仅仅获得这些数据是不够的,必须用大数据分析的手段,挖掘组学数据当中所蕴含的跟疾病相关的信息,即获得分子水平上跟疾病相关的知识。
第二,要建立分子水平上获取的知识和宏观临床疾病之间的桥梁,建立基因型和表现型之间的关联。这就需要发展一系列的医学信息学的方法,包括生物信息学的基础、生物网络和系统生物学的基础,有了这两个基础,才能使得组学数据应用到临床诊断和治疗当中来。精准医学实际上是要把组学大数据和当前的影像学、生化检验以及医生的临床经验紧密结合起来。
五问:精准医学现在处于什么阶段?
不管是中国还是世界其他各国,我认为,精准医学目前才刚刚上路,才刚刚开始。为什么这么说,虽然精准医学可以带来医学理念的根本性的变革,也许能带来新的大规模新型产业的出现,但是由于精准医学的实现还面临着诸多的重要的困难和挑战,因此精准医学还会有漫长的路要走。
下面,我仅举在组学和大数据处理当中个别的例子,来说明在精准医学的实现道路将多么困难。
六问:精准医学道路上的机遇和挑战在哪里?
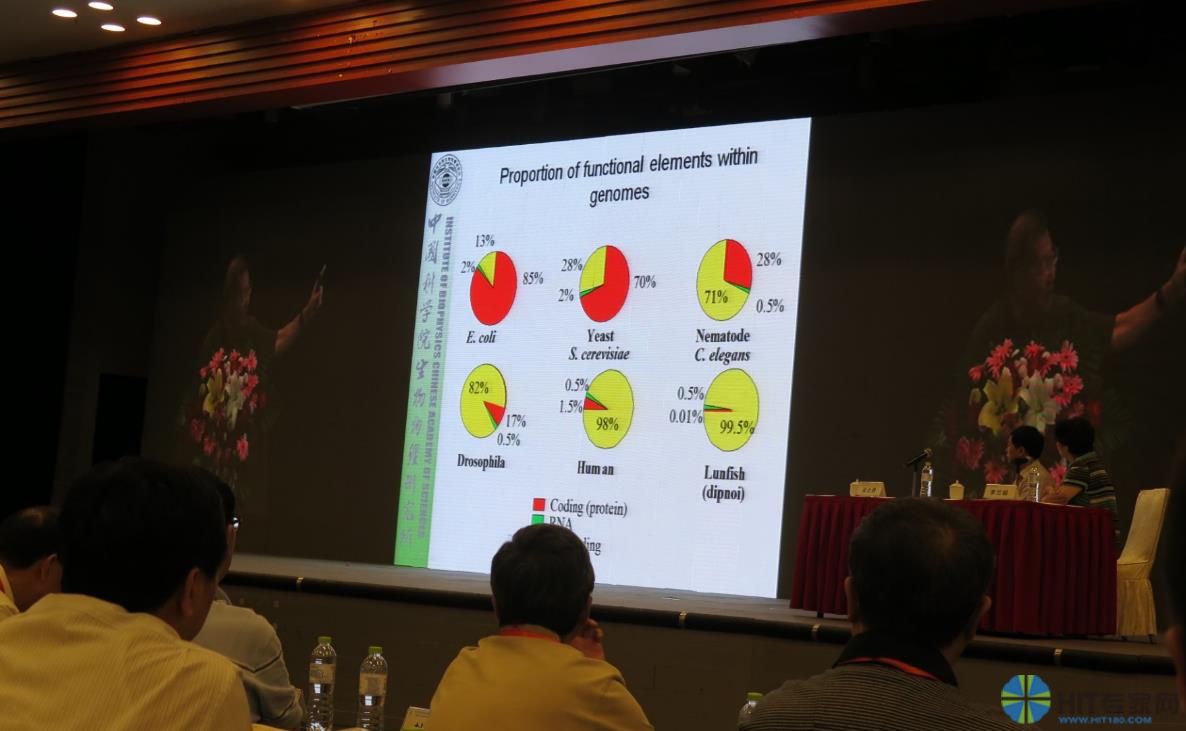
第一个例子,关于基因组学数据。人类目前能解读的仅有3%。
对于基因组来讲,还存在着大量的暗信息。大家知道,一段遗传密码由4个字母组成。如果每3000个字打到一张纸上,100张纸订成一本书,那么每个人的遗传密码可以订成这样的书的数量将达到一万本,如果一本书是一厘米厚,那么一个人的遗传密码都装订成书的话就是一万册,一万厘米就是一百米。那么如果2.5米是一层楼的话,每个人的遗传密码都可以装订成高度为40层楼房的一摞书,这一摞书里面就是你的遗传密码,而每拿出一页来都是这样的,那么你能读懂它,你就知道你的遗传是什么样的,你哪个地方有突变,容易得什么疾病。
问题是,现在虽然花大约1万元人民币就可以得到自己的遗传密码,并且刻录到一张光盘里,每个人都可以欣赏自己的遗传密码。但是你拿到这张光盘后,你能读懂多少呢?到目前为止,即便集中全世界的智慧,人类遗传密码能读懂多少?
事实上,能够精确说明生物学功能的部分只占遗传密码的3%——这就是我今天讲的最核心的部分!
大家可以到任何一个公司做一个基因检测,你可以得到你的整个遗传密码,但是你能分析的只是3%,当然这3%是有意义的,有很多疾病和这3%是有关的。但是,另外的97%也跟你的疾病有关,目前我们还无从知道。这就是我们现在对于组学体系研究的现状。这一点不清楚的话,我们就无法把握精准医学的实现的漫长的路和目前基因检测的有效性。
关于这一点,如果大家有兴趣,可以非常容易得到证实。2010年12月17日这期的《科学》评定了人类进入21世纪以后前十年在自然科学领域最突出的十个问题。第一个问题,就是基因组当中的暗物质。到本世纪的前十年,我们对自己的遗传密码的了解只是3%。其他这些系列,被统称为基因组当中的非编码序列。我特别要说明这一点,非编码系列将是我们精准医学存在的最突出的组学障碍,但是也是我们发展创造创新的巨大机会。
如果从生物演化来讲,传统认知是,生物越高等,我们了解的遗传密码的部分越多,编码蛋白质的基因一定越多。事实上,恰恰相反,随着生物从低等到高等,我们不知道的部分越来越多,我们了解的部分越来越少,这就是基因组学和比较基因组学的启示。
进入21世纪以来,全世界的科学家都在研究那97%是不是工作。如果工作的话,那么它就会有信息释放出来。事实上,那97%的非编码序列,每时每刻都在工作,每时每刻都在产生着新的分子,这些分子一定在执行新的生物学功能,因此到目前为止,没有人怀疑那97%的部分是有生物学功能的。虽然整体的规律不清楚,但是个别的例子已经出现了,证明这些非编码序列存在的重要的生物学功能。
我给大家举几个肿瘤相关的例子。有一个来自非编码序列的产物是可以导致前列腺癌的。另外有一个基因是可以导致白血病的。有一个基因,中国人很关心,至少有四个实验室在研究它,它是可以导致非小细胞肺癌的。这三个例子提示我们,虽然我们现在在临床对肿瘤的诊断,所有的诊断的分子都是蛋白都是那3%,而治疗的药物的也是针对那3%,但是,这三个例子全部来自97%,也就是说那97%也跟肿瘤有关,但时还从来没纳入到疾病的诊断和治疗当中。在这样的前提下,我们能做得精准吗?
所以如果不彻底地了解那97%跟我们的生长,跟我们的健康,跟我们的疾病有关的基因组学数据,当然不可能做到精准。如果我们把这里面的分子都了解清楚,我们对肿瘤、对其他严重疾病的诊断治疗一定能够大大地提高。
H19是一个非常重要的肿瘤抑制转氨酶,在座的医生们一定很清楚P53是非常重要的蛋白,如果正常存在就可以通过细胞凋亡的途径,使得癌变的肿瘤细胞灭亡。而这个H19是来自那97%也就是非编码序列的产物,如果正常存在的话,也可以帮助我们消灭癌变细胞。这个例子说明,那97%里面紧密的和我们的疾病和健康相关,而我们却不掌握它的核心信息。
我们蛋白的编码基因大约有25000个,来自97%的那里面有多少个元件存在呢?能否估计一下?迄今为止,由于伦理学法律学的原因,人还没有做到全部转录元件的刻录,我举一个日本RIKEN在UKHAMA做的小鼠的全转录文字刻录,证明从DNA转录到RNA发现一共181000个,其中编码蛋白的只有20000。言外之意,有161000个是来自97%的元件,而这些元件到目前为止我们发现了多少?有多少是确切知道的?据我了解,大约是1000个左右。我们还有160000个元件不清楚。大家知道,我们发现一个新的元件,能够稍微仔细的做出它的功能,这将是来自SCIENCE论文的很好的CANDIDATE。这展示的是还有至少160000个机会,大家努力一定会发非常好的文章。
另外一个例子,在这97%的领域里,2006年美国的两位科学家获得了诺贝尔奖。如果现在去统计,跟这3%有关联的有多少个诺贝尔奖获得者?大约不少于50位。而97%的未知领域,还有太多的机会,等待人们做出重大的发现。这也为我们创新提供了最好的机会,最好的战场。
对基因组当中暗信息的研究,一定会对疾病的诊断和治疗提供新的方向,一定会为全新的药物设计和研发提供全新的平台,为动物的新品种,新性状的培育提供新的可能。
一方面,从精准医学看来,我们组学当中还存在的巨大的障碍,但另外一方面,我们会有非常明确的创新的机会和方向。
七问:为什么组学大数据处理也存在非常多的困难?
首先是计算量大。组学数据也满足所谓IT界所谈大数据的4个V的标准。不管是基因组学数据还是蛋白组学数据,都是海量大数据。组学的大数据计算量大,或者说是数据量大。有两个特征,第一个特征,它不仅仅数量大,而且产生的速度极快。这是由于测序的需求和测序设备的发展。
第二,组学数据的噪音比较高。基因组测序很难把每一个字符都测到,往往是性噪比不好,缺失值又高,在这种情况下,如何实现分析?从数据源考虑,是增长非常快而且数据质量不够好的一份大数据。从研究目标的样本量考虑,我们获取样本往往是困难的。如果你和临床医生配合做某个肿瘤的研究,能做出几百例的临床样本已经很不容易了。但是大家考虑,我们任何一个数据建模的母体,往往自变量是成千上万的。用几百个约束条件来为这个母体来做估计,是不可能做到的。但是,很多临床应用从不考虑这些因素。这个结果实际上是不可靠的,稍微增加一点扰动,整个结果就全变了。所以这就是当前非常重要的问题,不是所有结果都是可信的,而没有人去衡量这个结果的可信度。要使得这样一个小样本的大变量的母体得到更加精确的结果,有两个办法。一是增加样本量,这是为什么美国、欧洲、日本,都要做上百万人的遗传密码。让边界条件大于自变量,这是一个数学本质。二是对于一个具体研究组来讲,你没有获得大样本的可能,怎么办?可以改变建模的体系,把母体缩小,让子体能够和样本量相匹配。
下一个问题,不仅仅样本小,在考虑组学变量的情况下,往往对同一种疾病组学变异位点是不是只是一个单异位点,比如说肺癌,用100个肺癌作为一个母体来处理的话,实际上,当你考虑基因型的时候,会变成非常非常小的亚单位,因此使有效的样本量变得更小,这是因为我们的样品是在不同组织、不同时期、不同状态下获取的,带有不同的变异位点,这是我们必须考虑的,不是你找了100个肺癌病人就作为一堆,这是不严肃的。
我下面要讲带有哲学意味的话,就是如何在精准医学尺度上考虑共同疾病。如何完成共同的变化,而共同的疾病什么才是特异的变化,没有这两个所谓医学哲学思考,药物没有办法设计。过度考虑个性化医疗,没有人敢做药,因为每个人都不一样,但是过分的考虑个性化的东西,谁也不能看病了。因为没有共同性的药物。所以这是更深刻的问题。
另外,我们知道,对于单独的基因考虑,是为把问题简单化了。实际上,所有的基因都是关联的,因此我们下一步的所谓医疗信息要考虑的基本问题,是这些基因之间复杂的网络关系,是动态的。不仅要研究组学数据,还要跟影像学、生化学结合起来,这是高度异质化数据的整合问题,当然也是更加复杂的,最后一个更加复杂的问题是数据共享问题。从1996年我们几个人就拼命给领导写信,促进数据整合共享。到目前为止,还有很多困难。最近我们很快会有几个大约十个院士的给国家起草一个咨询报告。我相信不解决数据共享的问题,我们将会面对大数据时代做小数据的事,不能充分利用大数据带来的数据建模,对我们这样一个国家来讲,对全民、对医生来讲都是非常可惜的。
因为时间关系,没有一一展开。希望大家批评指正。谢谢。(本文根据发言整理,未经本人审阅)



评论前必须登录!
注册