 HIT专家网
HIT专家网
来源:HIT专家网 供稿:腾讯健康
【开栏语】
当前,腾讯健康正在全力构建数字健康的“两面四桥”,借助自身储备的技术能力、连接能力,致力成为医疗行业信息化的“数字化助手”,实现“科技向善”的品牌愿景。HIT专家网将开设【腾讯健康专栏】,通过一系列技术文章介绍腾讯健康业务深耕方向、技术解决方案与落地案例等,敬请各位读者关注。
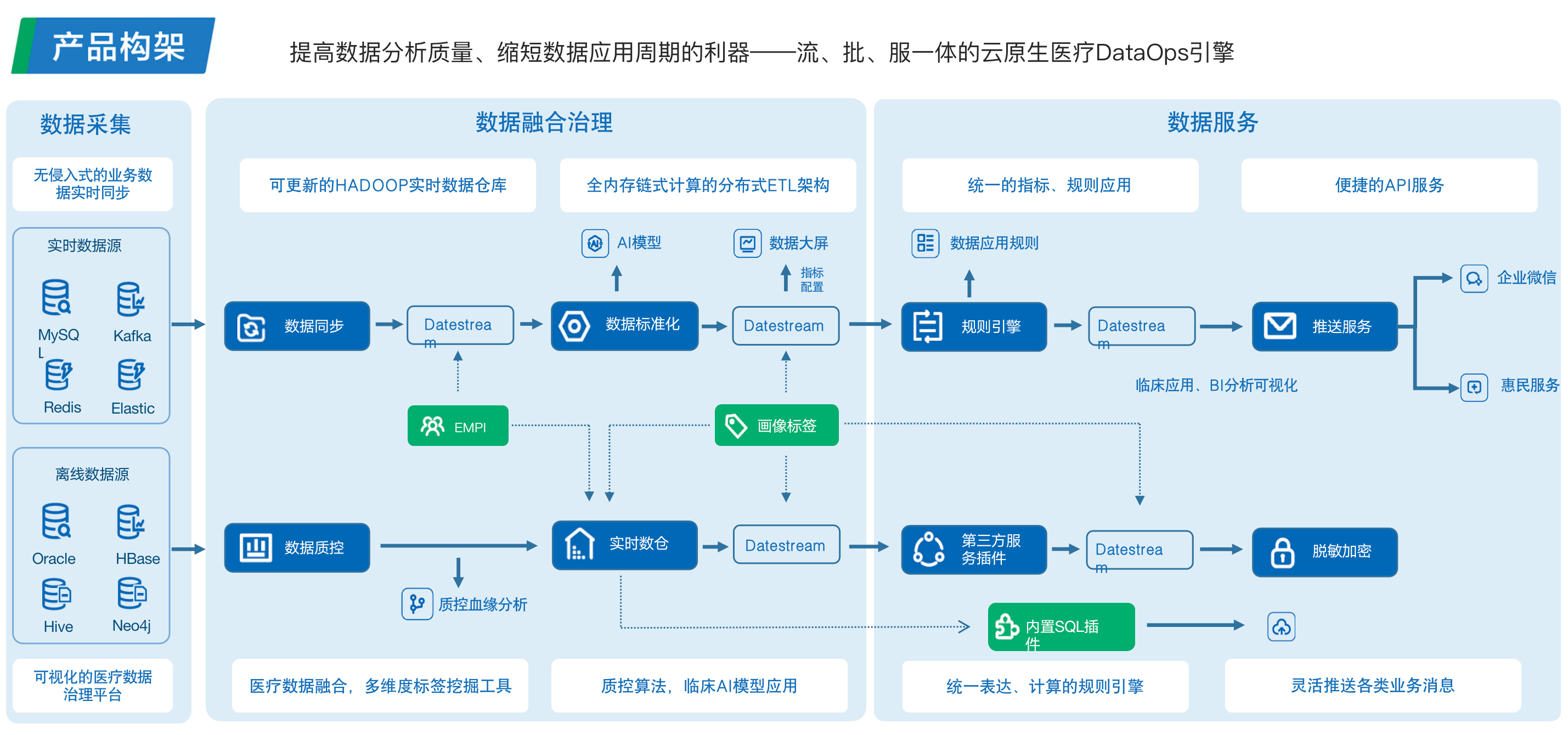
当前,医院已经积累了大量数据,这些数据通过医院的信息集成平台、CDR等系统,在便民应用、医护管理、医院运营管理等不同场景的数据查询、规则计算、统计分析等数据应用中发挥着重要的作用。日益庞大的数据量使得医院原有的业务应用运行速度变慢,新的业务场景也对数据提出更多需求。
许多医院都在面对这些问题:因为数据量过于庞大,统计一张月报表需要十几分钟甚至更长时间;因为并发问题,无法进行全院级的过程质控;因为技术限制,无法获取实时的患者就诊信息等重要数据。
如何才能让医疗大数据平台与相关应用“快”起来?支持大批量实时计算与查询的计算引擎性能,是解题的关键之一。
寻找适合医疗大数据特性的计算引擎
从数据应用角度来看,医疗大数据需要的技术支撑主要分为查询与计算。数据并发量、一次性数据计算的量级以及数据实时性要求,是选择大数据平台计算引擎时需要考虑的重点因素。
| 医疗业务场景 | 高并发I/O需求 | 海量数据读写需求 | 时延性要求 |
| 就诊360/健康档案等 | 低 | 少量计算 | 实时数据即时查询 |
| 运营分析/等级医院考核/综合监管等 | 低 | 大批量计算 | 离线数据即时查询 |
| 科研检索/数据探查等 | 低 | 大批量查询 | 离线数据即时查询 |
| 临床预警/重复检查等 | 高 | 少量计算 | 实时数据即时查询 |
| 疾控重点人群预警 | 高 | 大批量查询 | 离线数据即时查询 |
| 业务系统对接等 | 高 | 少量计算 | 实时数据即时查询 |
需要注意的是,支持高并发、大批量数据计算、即时出结果的先进技术固然很好,但它们对数据结构、应用场景、硬件设备等方面的要求苛刻,不太适用于当前医疗行业的实际需求,另一方面,行业厂商现有的技术和运维人员能力也不足以支撑。因此,技术不是越先进越好,而是需要根据医疗大数据特性来遴选相关最为合适的引擎技术。
现在针对大数据的组件技术非常多,比较常见的大批量数据实时计算与查询引擎包括Oracle、Hive、Spark、Clickhouse,以及腾讯OLAP查询引擎等。这些数据查询引擎有个共同特点,也即在开发过程中对现有系统的改造较少。
在医疗业务场景中,究竟应该使用哪个引擎?表2是在推荐配置的前提下,几种常见引擎在满足不同医疗业务场景需求时的性能横向对比。
| 医疗业务场景 | Oracle | Hive | Spark | Clickhouse |
| 统计门诊就诊人次(门诊就诊表500万人次) | 2.79 | 3.15 | 5.22 | 0.1 |
| 统计门诊年收费(门诊费用明细表5000万) | 12.23 | 10.26 | 13.21 | 0.17 |
| 统计近七日核酸数据(核酸数据1亿条) | 25.74 | 14.56 | 22.98 | 0.25 |
从表2可以看到,Clickhouse在单表数据查询方面的性能相当不错。不过,在多表关联查询中,尤其是超过2张表的情况下,Clickhouse的性能就会有所下降。
在此基础上,腾讯医疗OLAP引擎结合实际数据需求,从系统架构的不同层面对多个传统开源组件进行了整合、优化,可满足不同量级的多表查询使用需求,具体性能表现如表3所示。
| 医疗业务场景 | Oracle | Hive | Spark | 腾讯医疗OLAP引擎 |
| 医院统计门诊肺炎患者使用抗生素日均人次 (门诊就诊表500万、诊断表700万、 药品表2000万) | 130.1 | 118.26 | 57.16 | 2.86 |
| 卫健系统统计住院患者出院2-31天再入院率(病案首页100万、 病案诊断表500万) | 35.96 | 23.69 | 19.3 | 1.57 |
| 疾控统计核酸和疫苗关联,近一个月核酸结果与接种疫苗剂次分布情况(核酸检测表4亿,疫苗接种表5000万) | 190.55 | 101.21 | 67.81 | 3.18 |
4个秘诀,成就腾讯医疗OLAP引擎的“快”
对数据查询计算层面进行了大量的优化后,腾讯医疗OLAP引擎团队总结了4种可以有效提升计算引擎性能的经验做法。
其一,改进查询模型。实践显示,运用“查询模型改写”,能够提升效率。比如:通过物化视图大宽表预先聚合,可以提升引擎性能;利用字典表可解决Join问题;采用Hash方式接入数据并采用Collocate Join大表,可将引擎性能提升3-5倍。此外,还可通过建设数据业务宽表、巧妙运用BitMap、利用Array Join改写Union All降低重复I/O等方式;在数据仓库进行医疗值域码表的大量转换过程中,也可以大大提高即时查询的效率。
其二,提升CPU的利用率。腾讯医疗OLAP引擎的“快”,归功于“全面向量化技术”。一般而言,向量化通过“批处理”改善IPC(Instructions Per Cycle,每周期指令数),这种方式在加强内存、磁盘性能的同时,也使得CPU成为当前OLAP查询性能的瓶颈。有别于“部分”向量化,腾讯医疗OLAP引擎采用全面向量化技术,磁盘、内存格式按列存储,表达式、执行节点都尽量采用向量化执行技术。这样做的好处是,一方面可减少虚函数调用,提高CPU Cache利用率,另一方面也为SIMD(Single Instruction Multiple Data,单指令多数据) CPU指令的使用、编译器的循环优化以及减少分支调用创造条件,从而提高了CPU利用率。该项技术的使用,配合腾讯健康数据中台独有的SQL解析优化技术,将健康档案查询的字段投影剪裁与向量化技术结合,更好地提高了系统资源的使用效能。
其三,物化视图预计算。有别于传统的CUBE聚合,物化视图通过每次写入触发运算,将明细数据使用动态聚合成可迭代的中间状态,只需在中间态结果上进行查询即可获得最终结果,大幅降低查询耗时。腾讯医疗OLAP引擎在业务场景中广泛使用物化视图,并创造性地提出通过物化视图组合宽表替代Join场景,可以解决多协议指标宽表聚合的复杂问题,减少开发耗时(指标新增和维护)和使用成本(复杂Join或者Union All的多次I/O),提升查询效率。
其四,BitMap改进。引擎内核中的BitMap采用RoaringBitMap实现、利用BitMap And/Or中间态运算替换Join等操作,可以使得引擎在患者人群标签分析等场景时获得10倍的查询加速。但在数据量极大或极小等场景,这种方式还需要进一步改进优化。比如:在稀疏场景下的引擎性能退化严重,数据量大时读取大量I/O遭遇瓶颈且并行度低、函数支持也有限。腾讯医疗OLAP引擎通过切分BitMap实现处理并行化提速、利用disk/kv db重构存储加速I/O吞吐率、开启指令级算子等方式,进一步提升了引擎性能。
综上,根据医疗大数据的特性需求,利用技术手段有针对性地提升计算引擎性能,再回到不同的医疗业务场景中不断优化、改进,这就是医疗大数据平台“越来越快”的成长路径。腾讯医疗OLAP引擎已在宜昌市中心人民医院等用户医院落地,帮助医院更好地借助大数据的力量,赋能高质量发展。

精彩不容错过!

我们将尽快与您联系!
【责任编辑:秦勉】



评论前必须登录!
注册