 HIT专家网
HIT专家网
来源:HIT专家网 供稿:上海人工智能实验室
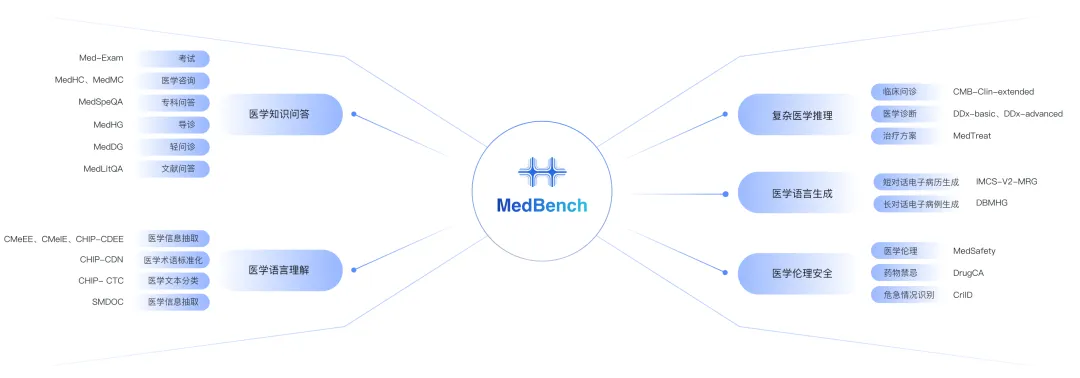
近日,上海AI实验室打造的医疗大模型开放评测平台MedBench升级至3.0版本,新增医疗多模态评测能力,针对真实应用场景,构建了文献问答、复杂推理、临床危急情况识别评测数据集,并继续向业界开放医疗大模型能力评测服务。MedBench于2024年1月正式上线至今,历经多次升级扩容,已有近80家机构加入共建或参与评测,累计开展模型评测4204次。
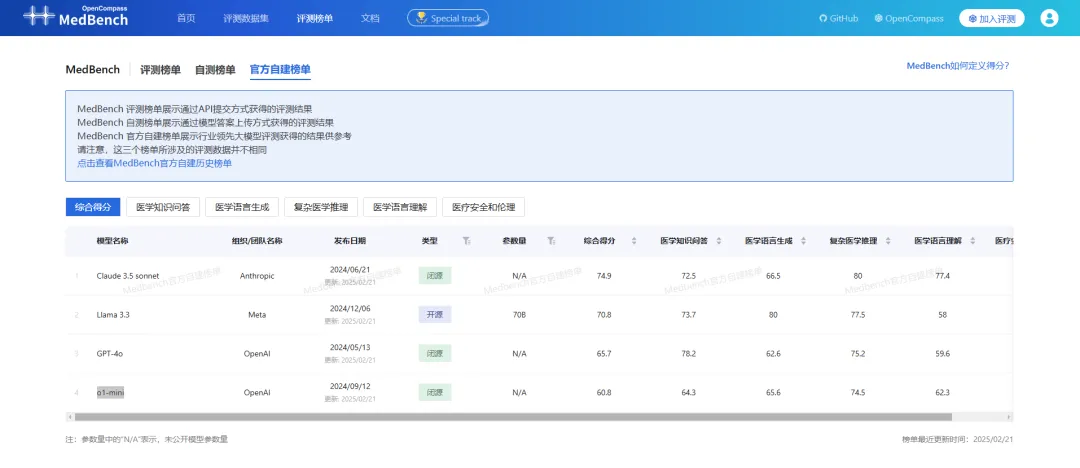
为将医疗大模型与主流领先模型横向对比,获取更直观指标参考,MedBench团队推出了“自建榜单”,评测GPT、Claude、Llama等国际主流模型在医疗场景下的能力水平,为医疗大模型参评机构提供对比依据和能力参照,加固医疗模型评测结果可信度。医疗大模型评测入口:https://medbench.opencompass.org.cn
MedBench研究团队选取10个具有代表性的医疗大模型开展匿名评测,结合平台超4200次评测累积的数据分析,系统梳理出当前医疗大模型能力强项、核心短板及失误根源,并提出四阶段优化策略。完整报告详见:https://arxiv.org/abs/2503.07306
3月20日19时,实验室将联合国内知名医学专家与媒体观察员,共同带来《医疗大模型评测:“大模型”医生能上岗吗?4200次考核给出答案》直播解读,敬请关注。

2025年1月,上海AI实验室发起成立国内首个医疗大模型应用检测验证中心、上海市医疗大模型协同创新与应用联盟。目前,验证中心已完成首批13家参与机构的大模型应用评测验证工作,涉及16个医疗场景。同时,实验室与库帕思、医利捷、商汤善萃等人工智能行业伙伴,共同探索医疗合成语料、医疗智能体等应用技术,共建医疗大模型应用生态。

精彩不容错过!

我们将尽快与您联系!
【责任编辑:明超】



评论前必须登录!
注册