 HIT专家网
HIT专家网
来源:HIT专家网 编辑整理:谭啸

10月25日,区块链在全国范围内迅速升温。
2018年南湖HIT论坛上,医疗行业的区块链品牌“信医链”首次亮相,彼时区块链正被报以怀疑的眼光。
时隔一年,2019年10月19日,上海信医科技有限公司CEO冯东雷博士再次来到南湖HIT论坛,介绍信医科技的最新发展:“今年一方面夯实产品线,另一方面做交叉研究,探索区块链和大数据的结合。”冯东雷博士在演讲中重点介绍了专科联盟如何基于区块链进行多中心科研大数据分析。以下为其演讲内容摘要整理。
应用区块链解决多中心临床科研痛点问题
当前,国家正在积极推进专科联盟、专病大数据中心的建设,各地在这方面都有强烈的需求,但还存在一些问题。
传统的临床科研存在六大问题:一是主要基于临床试验,周期长、见效慢,临床大数据技术可以作为补充手段,实现自动化获取数据。二是数据质量低,文本数据处理困难,需要大数据治理。三是难以快速找到合适的科研病例,需要大数据病例搜索;四是难以快速验证科研病例是否对研究有意义,需要大数据科研探索辅助科研选题;第五,从科研数据分析到论文撰写,缺乏方法,效率低,需要基于工具化的临床科研套路。第六,多中心临床科研,参与单位积极性不高,数据获取困难,需要基于区块链的多中心临床科研大数据分析技术。
“同时,基于全国性的专科联盟开展多中心临床科研已经是一种趋势。”冯东雷博士谈道,单中心临床科研大数据分析面临两大问题:一是样本局限性,单家医院的数据量有限,无论是数据本身的量级,还是样本的代表性方面都具有局限性,对此可基于区块链、安全多方计算实现多中心样本利用;二是研究局限性,单院区的研究课题与研究方向具有局限性,应基于多中心数据源开展联合研究。
而要开展多中心临床科研大数据分析,同样面临着问题:一是数据采集难,联盟内数据分布在各医疗机构,医院不愿意开放各自数据到中心端进行分析利用;二是联合研究难,联盟内数据分布在各医疗机构,医院的数据标准、编码方式等不完全一致,数据驱动下的联合研究较难实现。对这两大问题:一是利用区块链技术实现数据分布式、多中心的安全计算;二是在联盟内推行标准化电子病历及专科术语库应用,统一数据标准。
谈到联盟大数据的数据安全问题,冯东雷博士认为主要有三点:(1)安全共享,医疗机构不希望数据被合作方取走,不希望被外部互联网服务存储;(2)可追溯性,数据的使用过程难追溯,缺乏必要存档和证据溯查;(3)可监管性,数据的流通过程缺乏必要监管。
正是基于这些问题,冯东雷博士提出专科联盟大数据科研应用的建设目标:一是“区块链+安全多方计算”,解决数据安全问题;二是“大数据+人工智能”,解决数据使用问题,产生科研成果。
构建专科联盟标准化专病库
联盟医院首先要建立标准化专病库,然后才能基于区块链进行安全计算。
什么是“标准化专病库”?冯东雷博士认为,至少需要四个方面的“统一”:(1)统一的专病数据模型,面向科研和专病的数据模型;(2)统一的专病数据标准,数据元和值域代码标准化定义;(3)统一的专病术语体系,面向专病的疾病症状、体征、诊断、检验、检查、药品、手术术语体系;(4)统一的自然语言处理文本标注规范,医学实体、实体-关系等的规范化标注。通常是联盟牵头单位提出标准化方案,联盟单位参与讨论,达成共识后发布联盟标准。
专病库构建工具包括三部分:首先,基于统一的专病术语确定病种,基于疾病名称或诊断编码,系统能自动结合专病术语库中的同义词在院内CDR中抽取病例;其次,构建统一的专病数据模型,参考OHDSI OMOP CDM的观察型科研数据模型,提供类CRF表单界面,定义专病库所需要的内容(专病数据模型标准),包括人群特征、诊断、检验检查、用药、手术等;第三,基于统一的专病数据标准进行专病数据清洗,提供图形化的界面,将CRF表单的字段与原始CDR电子病历字段进行映射,使数据清洗过程自动化或半自动化。
构建专病库关键技术有二:
1.医学自然语言处理技术(NLP)
它能帮助实现电子病历结构化,首先把病历文本资料整理为医学信息,需要形成统一的自然语言处理文本标注规范;其次基于规范进行是实体识别,从文本中提取医学实体;三是实体-关系识别,识别文本中提取的各个医学实体之间的关系;四是实体链接,将文本中提取的各个实体与临床术语建立链接(同义词、上下位关系)。
2.专病术语体系库
(1)临床知识图谱。核心实体包括5种类型:症状、药品、检查、疾病、科室,不仅每一种实体有自己的记录,更重要的是建立了实体之间的横向关系,为后面的推理、搜索、统计建立了基础。冯东雷博士在现场展示了信医科技为复旦大学附属儿科医院做的“肾脏病专病临床知识图谱”。
(2)术语库构建。基于图谱构建术语时,同一疾病在ICD-10和ICD-11中可能有不同定义,既需要做标准化,又要基于ICD-10和ICD-11在横向之间做匹配,同时还要跟实际的诊断编码关联上。不仅是诊断,检查检验也存在类似情况。“在检验方面,我们基于申康医院发展中心38家医院进行检验同义词训练,构建检验指标术语库。”冯东雷介绍说,“除了同义词,还有上下位关系,有时候我们需要通过分类去查询、匹配、搜索、统计。”
基于区块链的安全多方计算
“2018年是我们打基础的一年,我们首先明确院内数据和区块链到底是什么关系,并不是全量数据都上链,那是不现实的,所以我们做了上链决策。实体数据还在院内,院内数据注册上链。”冯东雷博士谈道,“我们在链上维护虚拟专病库,实际上就是建立跨医院EMPI(患者主索引),还包括事件或文档索引,这是信医链要管理的,而实体数据还在院内。”
其次,信医科技基于通用区块链产品封装了医疗接口和服务。信医链产品基于国家互联互通标准,现在各家医院都在做互联互通标准化成熟度测评,很容易跟信医链映射对接,不需要大量改造,就可以快速上链。
2019年,信医链主要做了安全多方计算,从逻辑上把专科联盟数据关联起来,形成标准化专病库,联盟成员医院数据在物理上仍相互隔离,通过使用一些安全算法,让它们彼此可以使用每个节点的数据,但又拿不到其他医院的数据。
1.病例搜索
由于数据分布在各个医院,临床科研往往要把分布在各个节点上的数据搜索出来。通过搜索条件在病例大数据中进行全文检索,并通过年龄、性别等基本信息,以及科室、诊断、检验、检查、用药和手术等进行病例筛选,这样就能很方便地找到相关病例。
2.横断面分析
基于病例库,可进行横断面分析,让临床科研人员能快速对数据本身做判断。系统提供人群分布、并发症分布等预设图表。为了灵活地进行横断面分析,系统还提供各种图表可视化功能。
3.队列分析
系统提供交互式界面进行队列的构建与分析。通过全文检索和图形化查询形成视图,通过视图建立纳入标准和排除标准,进而选择起点事件和终点事件以及事件距离,以此构建患者的分析队列。
4.病例库挖掘
对于已经建好的队列和CRF表单,可对数据字段和病例进行筛选,用于科研分析。系统预设了PSM+逻辑回归、COX、KM和二维数据分析等多种分析方法,选择需要分析的字段即可进行数据分析。根据大数据挖掘结果,自动生成报告。
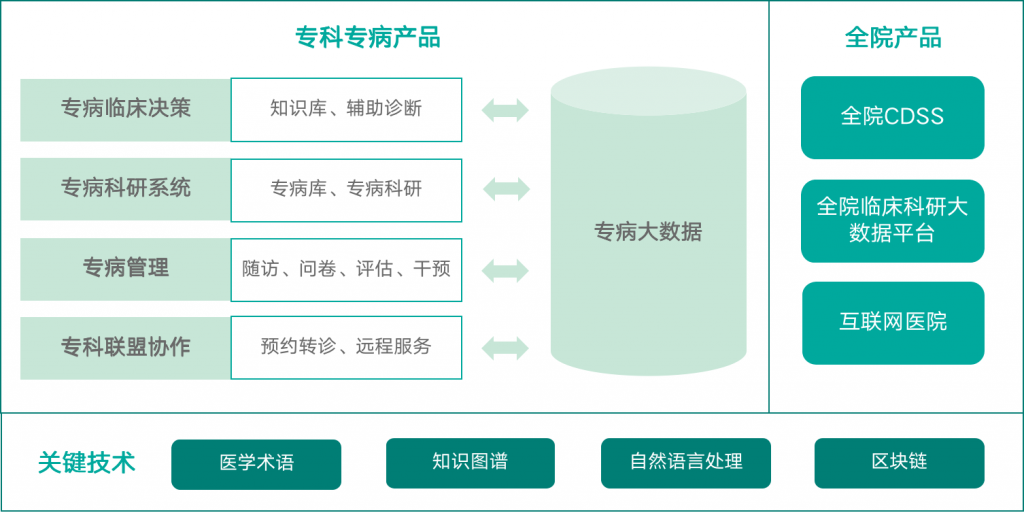
信医科技主要有两条产品线:一是基于“互联网+区块链“的专科医联体或专科联盟的建设和运营服务;二是面向科研的专病大数据与医学人工智能服务。2018年,信医科技主要发布了专科专病产品,例如专病大数据、专病知识库、专科联盟平台等,2019年则在专科专病产品的基础上重点发布了全院产品,如:全院临床科研大数据平台、全院知识库和CDSS、互联网医院等。
最后,冯东雷博士列举了一些典型案例,在大数据与人工智能方面:
- 上海中医药大学附属曙光医院,2015科技部863课题“心血管与肿瘤中西医大数据分析与应用”(2015-2017)
- 上海中医药大学,2018科技部重大专项“基于临床大数据的中药新药研发”(2018-2020)
- 复旦大学附属儿科医院,2017上海市经信委智慧城市项目“复旦儿科医联体互联网医院项目”(2017-2019),儿童肾脏科、内分泌科、康复科的专科大数据与人工智能
- 上海交通大学医学院附属瑞金医院,2018上海市科委医学人工智能课题“人工智能技术在胃癌综合治疗辅助决策中的应用研究”(2018-2020)
- 上海申康医联二期(2018-2019),参与电子病历大数据中心与专病大数据中心(新华-胆道)
在专科联盟与信医链方面:江西省医疗健康区块链试点;复旦大学附属儿科医院国家儿童医学中心互联网+肾脏专科联盟;江西沪赣远程医疗;上海申康医联工程二期长三角医疗协同区块链顶层设计及试点;江西省儿童医疗联盟等。
附:视频回放《冯东雷:基于区块链的专科联盟多中心科研大数据分析研究与实践》

想加入HIT专家网专业交流群吗?请添加“HIT专家网”小助手微信好友
(请务必注明姓名、单位名称、职务、主管技术或产品领域等实名信息)
【责任编辑:孙鹏】



评论前必须登录!
注册